
Barret
Tuesday, December 19, 2017 | 11 minutes
C# Advent Calendar 2017 - Using C# and Azure Cognitive Services Text Analytics to Identify and Relate Text Documents
One of the tasks that developers sometimes face in large companies (or even small ones) is trying to figure out how large sets of data relate to each other. If that data is text based, C# and Microsoft Azure Cognitive Services Text Analytics functions make this extremely easy to accomplish. In this post, I’ll walk through identifying language and parsing out key words and phrases that we can use to help match blocks of text together.
Setup
Database
For this demonstration, we’ll create a database with two tables. The first is a table of text entries that will represent our documents. Another table will store generated keywords from the API. We’ll use EntityFramework Core and SQLite to create a structure like this to keep it simple for this post:
public class TextAnalyticsContext : DbContext{
public DbSet<TextDoc> TextDocs { get; set; }
public DbSet<TextDocKeyphrase> TextDocKeyphrases { get; set; }
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseSqlite("Data Source=keyphrases.db");
}
}
public class TextDoc
{
public Guid Id { get; set; }
public string Language { get; set; }
public string Text { get; set; }
public List<TextDocKeyphrase> Keyphrases { get; set; }
}
public class TextDocKeyphrase
{
public Guid Id { get; set; }
public Guid TextDocId { get; set; }
public string Keyphrase { get; set; }
public TextDoc TextDoc { get; set; }
}
Azure
Azure setup is simple. You will need to add Azure Cognitive Services to your Azure account. It’s very easy to do and there is a free level that allows up to 5000 transactions a month. Note that a transaction consists of every document passed to every service. If you pass 100 documents to the language detection service, then to the key phrase extraction service, then to the sentiment analysis service, that’s 300 transactions in total.
Follow this link to add Cognitive Services to your Azure account using these steps:
Assuming you haven’t added ACS to your Azure account before, you’ll see a note that there are no Cognitive Services to display. So click the “Create Cognitive Services” button to get started. Otherwise, click “Add” in the top Cognitive Services menu.
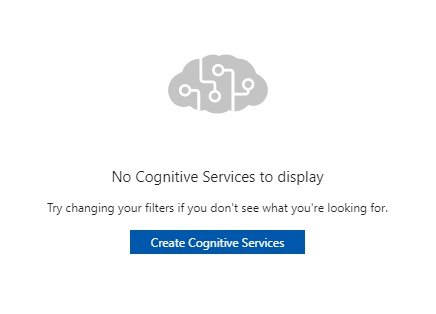
Cognitive Services
From the list of Cognitive Services, select Text Analytics API. The description will appear to the right. Click “Create” at the bottom. In the Create dialog, enter a name and change the Pricing tier to “F0 (5K Transactions per 30 days)”. This is the free tier. Either create a new resource group or select an existing one. When everything’s set, click “Create” at the bottom.
It will take a few seconds to create the service. When it’s finished, a screen will appear with some reference information listed as 1, 2, 3. For now, under “1 Grab your keys”, click on “Keys”. Copy both Keys to somewhere you can reference later. When you make calls to the API, you will have to pass in one of these keys.
Once you’ve copied down the keys, go to the Overview screen of the Text Analytics service you just created. From this screen, you will need the Endpoint URL that appears in the right column under Essentials.
Remember one other thing about the URL Endpoint. What’s shown is the base endpoint address. You will have to add the function name to the end of the URL when you make the call or you will get an empty response object. For Language analysis, the endpoint function is “languages”. So if you’re using the SouthCentral US data center, the URL is for Language Analysis is: https://southcentralus.api.cognitive.microsoft.com/text/analytics/v2.0/languages.
That’s it! The Azure end of the service is ready to go.
Making Calls
C# Application - Language Identification
There are two methods of accessing each of the functions in the Text Analytics API. The first is by making direct REST calls from any application to the API endpoint you created in Azure. The second is by using their C# NuGet package that has created a wrapper around making these calls. Please note that regardless of the method used, the length of each document is restricted to 5000 characters and you can pass in up to 1000 documents in each request. Further, the total request cannot exceed 1 MB in size. Go over any of these limits and your call will fail with an error. The 5000 character limit can be easy to run over, so be sure to put in some document pre-processing and checks to ensure you don’t go over.
For the REST call, you will pass in a JSON document list consisting of a list of documents, one for each batch of text to be identified. For each document, you will include an ID code and the text of the document using the following JSON format:
{
"documents": [
{
"id": "string",
"text": "string"
}
]
}
The result you receive will identify the most likely language for each document and a confidence score between 0 and 1. It will be a JSON formatted document including the result for each document and a list of errors, if any.
{
"documents": [
{
"id": "string",
"detectedLanguages": [
{
"name": "string",
"iso6391Name": "string",
"score": 0.0
}
]
}
],
"errors": [
{
"id": "string",
"message": "string"
}
]
}
The C# code you’ll need is a straightforward HTTP call to a REST API.
From the API Documentation:
var client = new HttpClient();
var queryString = HttpUtility.ParseQueryString(string.Empty);
// Request headers
client.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key", "{subscription key}");
// Request parameters
queryString["numberOfLanguagesToDetect"] = "{integer}";
var uri = "https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/languages?" + queryString;
HttpResponseMessage response;
// Request body
byte[] byteData = Encoding.UTF8.GetBytes("{body}");
using (var content = new ByteArrayContent(byteData))
{
content.Headers.ContentType = new MediaTypeHeaderValue("< your content type, i.e. application/json >");
response = await client.PostAsync(uri, content);
}
The alternative method for accessing the API using the NuGet package is simpler. It has built in error checks for the limits and provides you with predefined C# classes for the JSON request and response objects. In you Manage NuGet Packages for your project, add a reference to Microsoft.ProjectOxford.Text.
Then, in your code, add the following:
var lang = new LanguageClient(_apiKey);
lang.Url = _apiEndpoint + "languages";
var langRequest = new LanguageRequest(); //create a request to the Language Detection API
langRequest.Documents = new List<IDocument>();
langRequest.NumberOfLanguagesToDetect = 1;
using (var data = new TextAnalyticsContext())
{
var textDocs = data.TextDocs.ToList();
Console.WriteLine("Found {textDocs.Count} records to send");
foreach (var item in textDocs) {
//Do your pre-processing and error checks here
langRequest.Documents.Add(new Document() { Id = item.Id.ToString(), Text = item.Text }); }
var response = await lang.GetLanguagesAsync(langRequest);
foreach (var item in response.Documents) {
var rec = textDocs.FirstOrDefault(x => x.Id.ToString().ToLower() == item.Id.ToLower());
if (rec != null) {
var detectedLanguage = item.DetectedLanguages.FirstOrDefault();
if (detectedLanguage != null) {
rec.Language = detectedLanguage.Iso639Name;
data.TextDocs.Update(rec);
await data.SaveChangesAsync();
}
}
}
}
Currently, Text Analytics can identify up to 120 different languages. For documents where it can find multiple languages, the default response will only include the language identified with the highest score. There was a parameter you could pass in the request called numberOfLanguagesToDetect, but it has since been deprecated and you will now only ever get the top scoring language.
C# Application - Key Phrase Analysis
Now that we have identified the language of each document and stored it into the database, we’ll now need to create a list of keywords that we will use to associate documents together. As with the Language Identification, you can use either REST calls or the C# NuGet package. Again, as with Language Detection, the limits of 5000 characters and 1000 documents per call apply. With key phrase analysis, this can make pre-processing even more important. I generally will go through and eliminate any extra characters like extra spaces, line feeds, tabs, numbers, and common words like “A”, “I”, “the” and so forth. If your text records are longer than an average blog post, you may even have to split the records out into multiple documents to ensure you get a proper representation of key phrases.
Note that the number of languages supported for key phrase analysis is far fewer than language identification. At present, English, German, Spanish, Japanese, Danish, Dutch, Finnish, French, Italian, Norwegian, Polish, Portuguese (both Portugal and Brazil variants), Russian and Swedish are supported. Norwegian, Danish and Russian just came out of preview support last week, so they are constantly working on adding new languages.
For a REST call, you will need to pass in a JSON formatted list of documents. Each of the documents consists of three strings. The first is the language of the document that you retrieved in the previous step. The second is an ID. Again, we’ll use the database GUID ID. The last is the text of the document. In the header of the REST call you will need to include the API key that you saved when you created your Azure endpoint for Text Analytics. The body structure of the call looks like this:
{
"documents": [
{
"language": "string",
"id": "string",
"text": "string"
}
]
}
What you receive back is a JSON formatted response that includes a list of key phrases and/or errors associated with each document you sent.
{
"documents": [
{
"keyPhrases": [
"string"
],
"id": "string"
}
],
"errors": [
{
"id": "string",
"message": "string"
}
]
}
Whatever results you get you can store back to the database for each of the documents.
The ProjectOxford NuGet package again makes this extremely simple to carry out.
var keyphraseClient = new KeyPhraseClient(_apiKey);
keyphraseClient.Url = _apiEndpoint + "keyPhrases";
var keyRequest = new KeyPhraseRequest();
keyRequest.Documents = new List<IDocument>();
using (var data = new TextAnalyticsContext())
{
var textDocs = data.TextDocs.ToList();
Console.WriteLine("Found {textDocs.Count} records to send");
foreach (var item in textDocs) {
//Do your pre-processing and error checks here keyRequest.Documents.Add(new KeyPhraseDocument() { Id = item.Id.ToString(), Text = item.Text, Language = item.Language });
}
var response = await keyphraseClient.GetKeyPhrasesAsync(keyRequest);
foreach (var responseDocument in response.Documents.Where(x => x.KeyPhrases.Any())) {
var rec = textDocs.FirstOrDefault(x => x.Id.ToString().ToLower() == responseDocument.Id.ToLower());
if (rec != null) {
foreach (var keyPhraseItem in responseDocument.KeyPhrases) {
var keyPhrase = new TextDocKeyphrase() { Id = Guid.NewGuid(), TextDocId = rec.Id, Keyphrase = keyPhraseItem };
data.TextDocKeyphrases.Add(keyPhrase);
await data.SaveChangesAsync();
}
}
}
}
From my experience, if you send a document of nearly 5000 characters worth of words, you will typically get back between 60 and 100 key phrases for that document.
C# Application - Find Relationships
Now that we’ve obtained a set of key phrases for each document, it’s time to figure out relationships between our text records. One approach to go about this is to create a relationship score based on the number and type of matching key phrases that documents share. Like Azure Text Analytics’ Language Detection API, we’ll use a 0 to 1 based scoring system.
We’ll need to iterate through every pair of documents in the table and create a relationship score for each pairing. You can use whatever approach you like for this, but for this post we’ll just use simple, and very ugly, nested ForEach loops.
We’ll calculate the score of the comparison by using a weighted score for each key phrase. Longer keyphrases (3 or more words) will get a score of 5.0. 2 word keyphrases will get a score of 3.0. Single word keyphrases will get a score of 1.0. We’ll add up the scores and divide by the maximum possible score if all keyphrases were 3 words or more to get ourselves a total weighted score between 0.0 and 1.0. As I said, it’s ugly, but it demonstrates how we can compare the results to determine if two documents are related.
The code might look something like this:
using (var data = new TextAnalyticsContext())
{
var textDocs = data.TextDocs;
foreach (var textDoc in textDocs)
{
data.Entry(textDoc).Collection(td => td.Keyphrases).Load();
}
foreach (var textDoc in textDocs)
{
//create a simple list for easy matching
var keyList = new List<string>();
foreach (var keyPhrase in textDoc.Keyphrases)
{
keyList.Add(keyPhrase.Keyphrase);
}
foreach (var textDocToCheck in textDocs.Where(x=>!x.Id.Equals(textDoc.Id)))
{
var matchKeyList = new List<string>();
foreach (var keyPhraseInMatch in textDocToCheck.Keyphrases)
{
matchKeyList.Add(keyPhraseInMatch.Keyphrase);
}
var intersection = keyList.Intersect(matchKeyList).ToList();
//now we'll implement a rudimentary scoring system
var score = 0.0;
var maxCalc = intersection.Count * 5.0;
foreach (var intersect in intersection)
{
var split = intersect.Split(" "); //rough count of words in keyphrase
if (split.Length >= 3) score += 5.0; //we'll weight longer keyphrases heavier
else if (split.Length == 2) score += 3.0;
else score += 1.0;
}
var weightedScore = score / maxCalc;
Console.WriteLine("Match Score for {textDoc.Id.ToString().Substring(0,6)} against {textDocToCheck.Id.ToString().Substring(0,6)} is: {weightedScore}"); }
}
}
And the final result is a list of scores for how the various documents relate to one another.
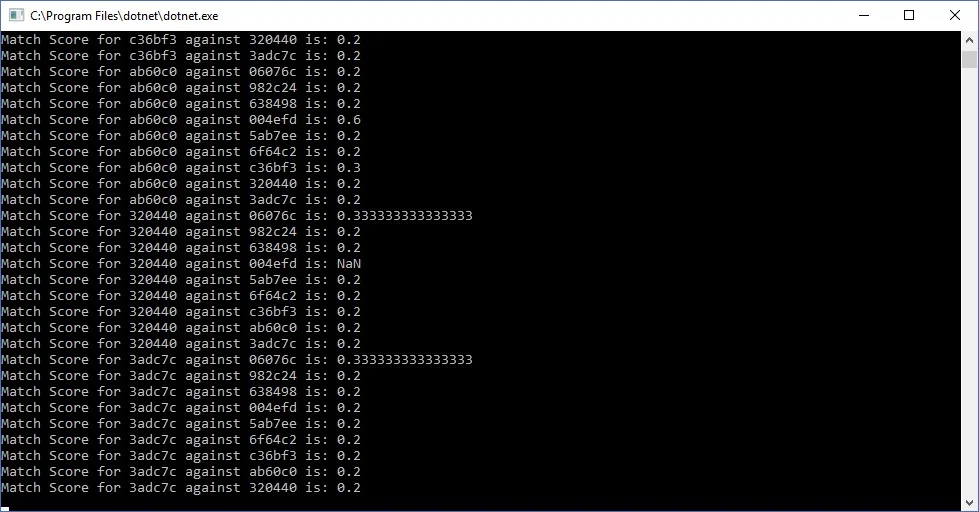
CognitiveServices2-1
Text Match Results
My test data consisted of text from 10 random blog posts taken from across several developer focused blogs, including my own. As you can see from the above, most of the data wasn’t particularly related to each other, but you get the idea.
Azure Cognitive Services Text Analytics and C# make it much easier to parse, identify and match up sets of text. It’s already saved me quite a bit of time from writing something similar myself. If you find yourself needing to identify a bunch of text docs it can certainly help you as well.
